These Aren’t the Phish You’re Looking For
An Effective Technique for Avoiding Blacklists
I promised myself I would never do another phishing blog out of respect for the roughly five hundred fifty billion infosec articles already out there on the same subject. It turns out I’m a big ‘ol liar. While working on my PhishAPI framework during a phishing engagement for a client, I believe I stumbled upon something significant I wanted to share with the community. At least, it is for me and greatly improves my success rate as a red team security consultant, and there should be a good lesson here for blue teams as well. My research took me down a long but enjoyable adventure over the last month and I learned a great deal about how sites end up on blacklists, who shares information behind the scenes, and ultimately, how to completely bypass ending up on a blacklist altogether. I hope you find it interesting or helpful in some way as well! If you’re Disney, please don’t sue me.. I’ve been a Star Wars fan for ages and will be making cringe-worthy puns throughout. (I just lost 50% of my readers already.. )
The Issue
I really enjoy phishing clients. It’s more like a video game for me with the tool that I developed and I get so geeked out to see real-time hashes, browser hooks, and credentials (with trophies!) rolling into our Slack channel. The down side is that I’ve noticed over the years things have gotten a little more difficult. This is in part thanks to an advancement in machine learning and link inspection technologies which proactively detect phishing attempts and fake portals designed to capture credentials. I’ve known for some time there are also proactive anti-phishing Twitter bots and Certificate Transparency (CT) log monitoring tools out in the wild looking for these sites, not to mention network security products which inspect DNS and web traffic for Newly Observed Domains (NODs). I’m careful to buy a domain in advance before an engagement but not set it up too early to tip anyone off, while at the same time discretely trying to obtain a certificate and prepare my landing pages and campaigns for go time. The timing is becoming less and less relevant as I find my landing pages (and my API occasionally, despite my tricky XHR requests) ending up on Google’s Safe Browsing Site as a phishing domain anyways. You’ve seen these.. the big red “WARNING” pages Chrome displays, even if content like tracking pixels reference the domain in the body of an email. Score one good team, but that’s not great for me when I have to move everything to another EC2 instance with a different IP address at the last minute and purchase new domains that haven’t aged yet. It makes me look like a bad phisher-person and I like my domains like I like my wine.

Why does this happen though? I mean, specifically in my case, I wanted to know exactly what action resulted in it being on a blacklist. Was it because I shared the link internally with my team over Slack or Gmail? Was it because my client shared it internally with their team and someone marked it as spam? I don’t want to do this in the future, always afraid of which actions are going to undermine my efforts. As part of my PhishAPI program I get an alert with an IP address whenever someone opens my email (if images are allowed) and I have noticed in the past that Google will inspect links and images before they reach the recipient. I know this because the IP address in the alert belongs to Google (ORG) if I do a whois lookup to see who owns it. Sometimes, the email will land in spam without ever touching my inbox. Is this a result of the inspection that occurred? Who else inspects my links? I know of companies who offer these professional services and a lot of my clients even use them. I don’t want want my content to be inspected so I started thinking of a way to get around this. I decided blocking Google and others in my host firewall wasn’t a good solution because it may look more suspicious if it’s not reachable at all.

The Idea
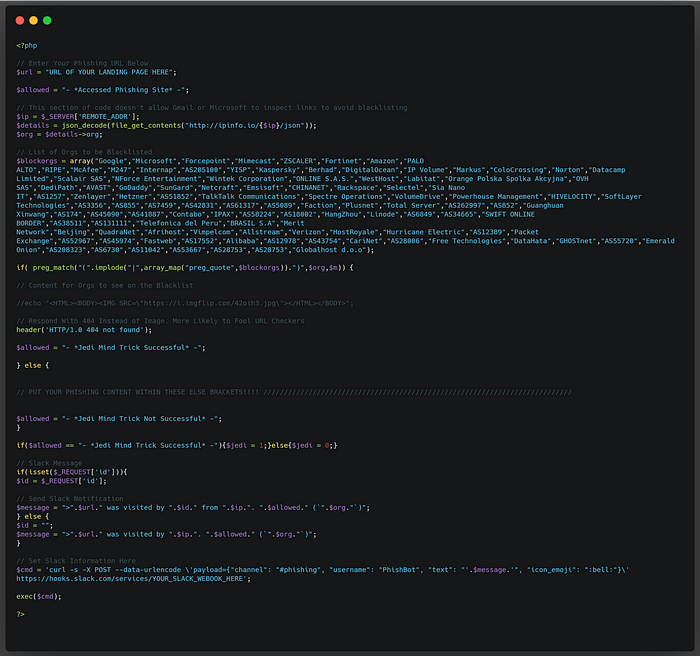
On my login forms which are cloned, modified landing pages, what if I were to simply check the requesting IP address and if it belongs to Google, use an IF ELSE statement with some server-side code to respond with different content than everyone else? I did something like this in my blog last month to thwart DoS attacks against my server when I frustrated some black hats, by responding with a 404 and adding their IP to iptables if the request wasn’t from Python. In this case, I could make it so that if Google inspects my link they’ll just see a simple page but if my target access it, they’ll see the phishing page in all of its glory. YES!

Except, it didn’t work. It did appear to delay the time it took to end up on Google’s Safe Browsing list as malicious. Also my client was using Microsoft O365 with Mimecast so using a Jedi mind trick would only work for Google recipients. I altered my landing page code so that ANY traffic coming to it would report the client’s IP address, ORG info from whois, and tell me if they saw just an image of Old Ben or the actual phishing page. I figured this would give me a better idea of other orgs that may be sharing threat intelligence information behind the scenes and I could add them afterwards to my script for the next round. Better yet, if I implemented this from the beginning before my domain and cert were applied, I could see which security orgs are reaching out to analyze my site, and subsequently block them as well! I would end up putting these “orgs” in an array as I went along. BAM, a blacklist for the blacklisters. Great, now James Spader is going to come after me too.
My Research
Instead of blocking each company by a range of IP addresses, I simply looked for “Google” or “Microsoft” anywhere in the “ORG” response from whois. I would email a link to my page to myself from another Gmail account and watch Slack as an alert popped up. I again geeked out knowing a bot somewhere belonging to Google was fooled into thinking my site was just an image and nothing more, while the rest of the world saw something entirely different. At this point I realized (here’s the takeaway for our blue teams) that these companies should probably check links from multiple, non-attributable sources before determining if the site is malicious or not. That site was already determined to be malicious previously, so I went about purchasing six more and I had a plan for each one to better understand and rule out assumptions on how this all fits together. I was going to use..(wait for it).. SCIENCE!
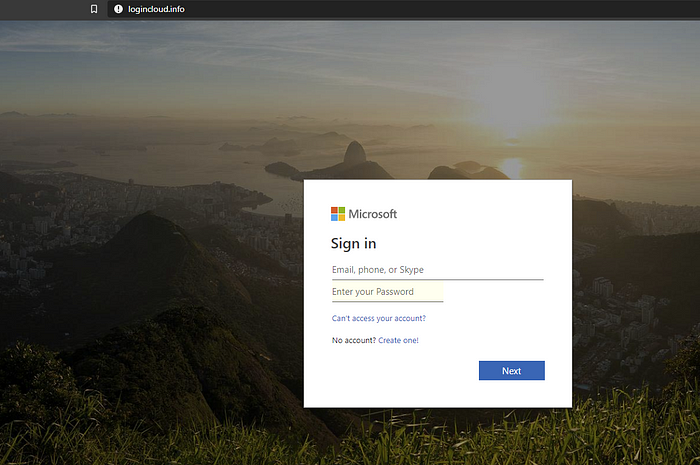
My new domain (don’t worry I won’t go through them all) was msoutlook.online. I had never purchased an “online” TLD before and “I just wanted to see a blue duck”. If I’m being honest though it was $1 USD. I set this up with the code I mentioned but I added a MySQL database back end to collect statistics for me. The Slack alert was modified to tell me if the “Jedi mind trick” was successful or not. I also added an “id” parameter I could pass along with the URL in order to track who the recipient was I was sharing the link with, to better identify them. Immediately after acquiring the domain and pointing the DNS record to my EC2 instance, I got a two hits in Slack. I waited 20 minutes and acquired a certificate from LetsEncrypt (again, free) and started getting hits from what I assume are security bots chasing CT logs (I later confirmed this to be the case). Avast was among one of these according to the “ORG” name. Awesome! Let’s add them to the list so they only get Obiwan next time. I still had a lot of questions in my mind at this time. Are these orgs pretty static and how many of them are there? What if they don’t all use IPs they own like Avast, Google, and Microsoft? What if I can’t block them all or I’m forced to block entire ISPs or ASNs? Did R2 know the whole time?!

The next thing I wanted to do was to start detecting (and blocking) other orgs like McAfee, urlscan.io, Kaspersky, Palo Alto, and Forcepoint (webroot), to name a few. My goal was to have a comprehensive list and ultimately not end up on any blacklists, if that was possible (Spoiler Alert: It was). I found a wonderful, recently updated list of URL inspection resources on Zeltser which included these and also many others I wasn’t as familiar with.
I decided to start with VirusTotal and immediately began getting bombarded with requests from the (at the time) eighty available vendors, including Google and Forcepoint again. I used my “id” parameter to specify “virustotal” so I could track who was sharing the full link and who was sharing the domain. With the exception of one request from a residential ISP, everything else seemed to originate from a specific company and a few were from cloud providers I knew my clients wouldn’t have egress traffic from. This was looking promising! I quickly added these new orgs to my block array and checked Google Safe Browsing (GSB). Checking GSB was passive and did not result in any hits, so I felt comfortable checking this over and over again to see if and at which point Chrome would be marking my site as malicious. As expected, it was marked as malicious eventually since most of the providers saw the fake Microsoft login portal instead of the Jedi mind trick. Virus Total also had a pretty awful score with the “Phishing” designation. I continued to manually do this for every URL inspection site from that Zelster resource until I had a pretty concrete list of orgs. This took a very long time but was fun to see the different “id” values pour in.



I decided it was time to try again with a new domain that wasn’t burnt yet and I got a new IP for the same EC2 instance to assign it to. The second round was really promising because many of the orgs, not necessarily the same IP addresses, were repeating. However, there were a few new ones for the second round and even one more new one for the third attempt I hadn’t seen yet. Each time I was discouraged when eventually GSB showed my site as “Deceptive”. I realized in the third attempt that it only took one request from VirusTotal (I know this because of the “id” param) to result in a GSB deceptive rating. VirusTotal was showing 4/80 detections, so I could tell that some of these vendors rely on others or use the same egress points to do their testing. I did see a lot of “Forcepoint” and “Google” being used by free url scanners on the web, so some of these are redundant anyways. urlscan.io was the most comprehensive aside from VirusTotal and used multiple IPs from different orgs, so I’m personally going to keep using them as a security researcher!

Experiments
I felt I still needed to understand why one visit without the Jedi mind trick would result in my site being blacklisted eventually, even though I wasn’t planning on using VirusTotal and other URL checkers for real campaigns. I was already seeing big promise in my phishing campaigns based on the VirusTotal scores and positive initial GSB results. I set up a few experiments to try and find out what was happening.
My first theory was that maybe the domains were “suspicious” all by themselves, but that seemed crazy to me that someone would be making the assumption somewhere that “msoutlook.online” was malicious just because of the name and not because of the content. Besides, maybe there’s a “Ms Outlook” who has a blog about positivity? Who’s to say? Maybe its the fact that the domain wasn’t very old, but that couldn’t be the only factor or all new sites would be blacklisted by default. As a control I set up another site with an obviously malicious domain (herephishyphishy.site) which only showed an image to everyone, and would let me know in Slack if they got the Jedi mind trick or Leslie Nielsen. This time around every request was on the blacklist, so it wasn’t necessary to mask the phishing page anyways. I checked all of the URL scanners against this URL again and watched the traffic pour in but even days later VirusTotal and GSB still showed 0/80 detections and was “Safe”.


The Breakthrough
Finally, I purchased a random domain (cbraz2020.online), waited a few hours (not days) and repeated the experiment. NO DETECTIONS! I saw a lot of traffic come into Slack and I crossed my fingers and jumped with joy each time “Jedi Mind Trick Successful” appeared on the screen. THIS. WAS. AWESOME! Not only could I avoid being casually inspected, I could throw it out there to the world and still get a perfect score. I self-reported my phishing URLs to Microsoft, Google, US-Cert, and a number of other vendors and still didn’t end up on a phishing list because when they came to take a look, they apparently determined there was nothing but a meme. I even took this a step further in another experiment where Palo Alto had detected my site initially as malicious (before I had them on my blacklist) and submitted a request for a reevaluation/reclassification. They emailed me back the next day and agreed that instead of “Phishing” it should be classified as “Computer and Internet Info”, which I can also assume is the generic category an image of an old washed up Jedi in Tatooine would receive. Talk about moving from the Dark Side to the Light Side!
Similarly, I received a notification from Amazon which contained a forwarded message from Netcraft, informing them that I was hosting a malicious site targeting their client, Microsoft. Ironically they emailed me back immediately and thanked me for taking quick action to remove the bad content. I didn’t, I just added them to the blacklist and they must have checked again later.

As a final sanity check, I created an additional domain (microsoftoutlook.site) and this time only showed the actual phishing page to everyone (so no image), while still recording if the visitor was on my blacklist or not. This allowed me to add a couple of additional outliers but was also very informative. I discovered that there was an exponentially large increase in the number of visits post-certificate creation. Many of these visitors were repeat visitors already on my blacklist from VirusTotal, so it seems reasonable to assume those orgs either also proactively look at new certs for potentially malicious activity or someone is submitting sites to them for analysis only after the original visiting bot determines the site is suspicious. I know this is the case with urlscan because when I submitted my own link for analysis 30 minutes later, I was already beaten by two prior scans, one from an API and one from “certstream”. I then submitted the site to VirusTotal and it already had a poor reputation, which I expected. It was fun to see Microsoft themselves analyzing my knock-off Microsoft portal.


Another thing I learned from this is that if protections aren’t put in place prior to the domain and certificate being issued, you’re much more likely to end up on a blacklist out of the gate, which is likely what was happening to me on these earlier phishing engagements. Even if you don’t use my Jedi mind trick technique, it seems likely you will maintain a lower profile for longer and avoid blacklists if you initially host the site with some other content and replace it with your “malicious” content just prior to starting the engagement.
Interesting Stats Maybe?


Closing Thoughts
This technique, if it has been done before (its so simple I have to believe it has), must not be very well known in the industry. I’m making this assumption because I’m not aware of it myself and I searched around prior to posting this. My research shows its also proved to be wildly successful and seems easy enough to thwart, otherwise. If its not new (as I often times think I’m the first-to, only to find out later its been done before in infosec) I hope I’m bringing some much needed attention to this attack vector. It makes me think about all of the other potential use cases such as sites with malware based on client vulnerabilities, ads, and unfurled URLs, to name a few off the top of my head. This adaptive behavior also reminds me of malware that avoids analysis by behaving differently when running within a virtual machine, for example.
I’ll certainly be using this technique until it gets less effective, hopefully due to my findings here. Something I didn’t try (yet) but I can imagine is a one-off scenario where a victim reports a link as suspicious from their email client. If you’re always monitoring who looks at the site and they’re not already on the blacklist, you can start small and add that org for the rest of your campaigns. Another application of this technique may be a whitelist approach instead of the blacklist one I proposed here. If you knew the target/recipient’s egress org, you could only show phishing content to them and “ignore the man behind the curtain” to everyone else. I also modified my code for real-world purposes to respond with a 404 instead of a funny meme, because I’ve noticed less follow-up traffic when it appears there’s nothing there at all.
I think the main takeaway here for myself is again the reminder that the web is dynamic. We should never assume sites we visit are the same for everyone. Malicious URL checkers and researchers should check from multiple, non-attributable sources. In addition to this, maybe these URL checkers and involved vendors should share notes with each other to compare hashes and screenshots for HTTP responses to know if they’re all seeing the same thing, if they aren’t already.
I feel I have a fairly comprehensive blacklist already from my research so I’m including it in my PhishAPI code on GitHub. I plan to include it later as a function and can be an external list, but right now only the API itself supports it and you’ll need to add it manually to the landing pages. Feel free to check it out if you’d like! At least at this moment it seems to cover most of the malicious URL scanners and bypasses the blacklists I’m aware of. I’m sure it can be improved upon as there are so many other vendors who inspect links as well. I would also think if someone wanted to, a centralized repository could be created and maintained by the community to stay updated and current. Otherwise you’ll want to test this on a throwaway account before an actual phishing campaign to make sure your blacklist is current. I can’t imagine it going stale quickly because its based on the org and not the IP, unless vendors start taking my advice.
Lastly, I would have loved to have kept this to myself and benefit from bypassing the blacklists for my own assessments, but as a white-hat researcher I would rather this be public knowledge and I would like to see this not be an effective tool for the black hats. Stay safe out there!